The Smile of Murugan
I believe strongly in the importance of preserving knowledge and sharing it. A book that I find important and in need of better preservation and dissemination is The Smile of Murugan. I am happy to say that we (Tim and I) have made a digitized form of the book that is much easier to read, search, and share.
The Smile of Murugan - a book about Tamil literature throughout history (web, ePub, PDF)
One of the illustrative parts of the book is this map
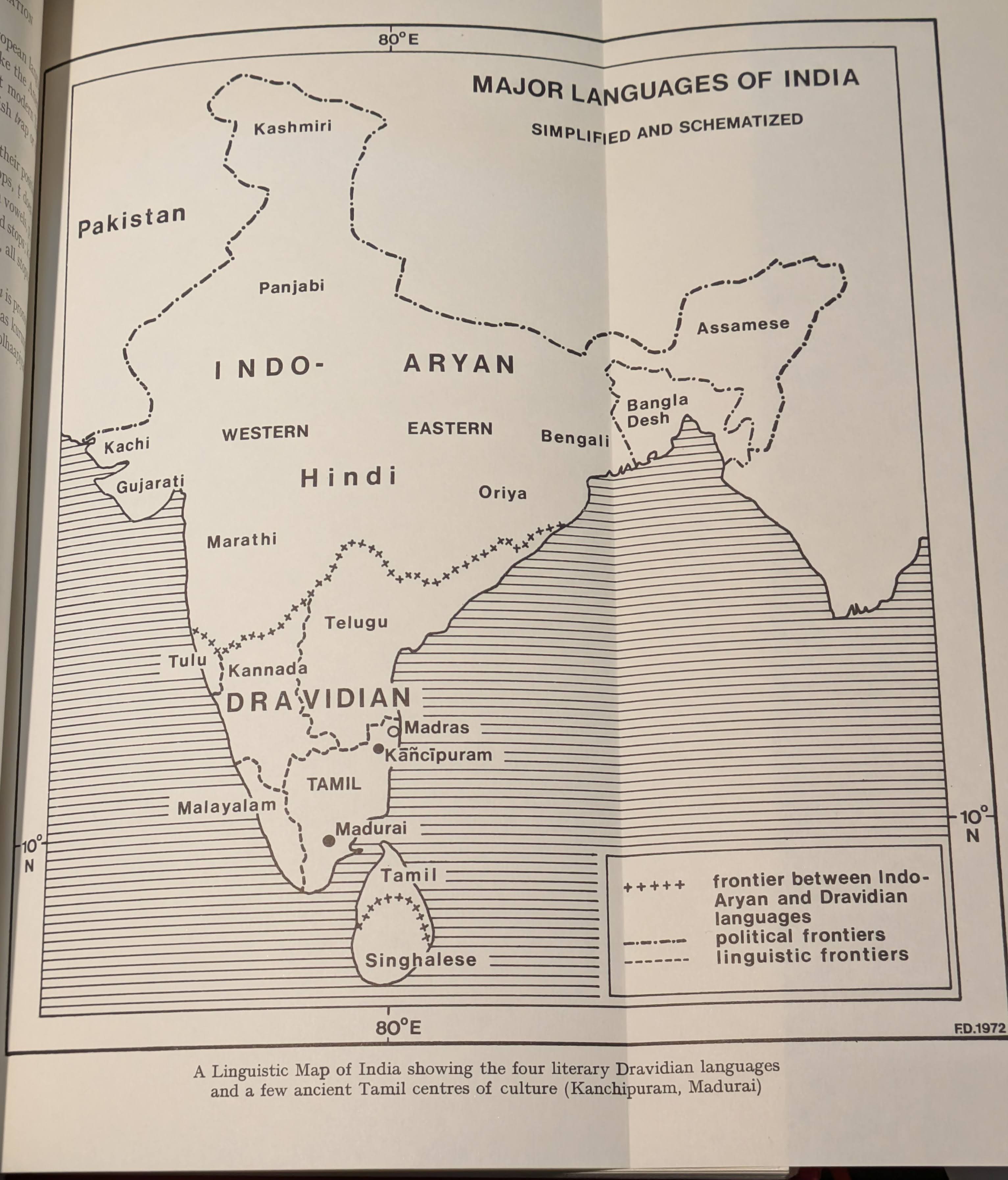
In a glance, you can already see the diversity of languages spoken throughout South Asia, including language families. You can already begin to appreciate that most recognizable large countries in modern South Asia have multiple languages spread all throughout, and some languages exist across multiple countries.
In addition to the book is available in its web form, it’s also available as an ePub and PDF. Personally, I found the best experience for reading to be via the ePub on a computer. For mobile devices, the web version works well, and the ePub should work well too.
Tamil history has been an interest of mine, especially because it has felt both shrouded in mystery and highly contested. The extent to which Tamil language, kingdoms, and empires had an impact on the world, seems largely untold. Paradoxically, many Tamils themselves are unaware of large sections of their own history, yet people (Tamils and non-Tamils alike) have strong opinions about it. For a long time, estimating the antiquity of the language, and by extension the civilization, has largely been done solely through literature, and thus contested. But archaeological evidence has been unearthed in modern day Tamil-speaking lands that correspond to lands and periods of ancient Tamil kings attested to by the literature, and this gives opportunities to compare and corroborate what we know. Multiple ongoing archaelogical excavation sites in Tamil lands are turning up new evidence that is radically changing what we thought we knew, and the Keeladi site is just one such example. And of course, the questions of “Where did Tamil and other Dravidian language family speakers come from?”, “Where did the people of the Indus Valley Civilization go?” come to mind after that.
Learn Tamil https://www.learntamil.com - lessons on Tamil grammar
History is important in the context of learning a language, which is an insight I have come to relatively recently. Teaching language is important, but introducing concepts of traditions and history give learners a better appreciation of the wider context of human culture they are getting a window into. I take a lot of inspiration from the story of the Native American / First Nation Myammia people (also known as Miami), whose language went extinct, but they amazingly revived the Miami language from the dead. The end part of the audio story, almost like an epilogue, about how the introduction of the history class in the 2nd year of having the language class changed the attitudes of the language learners, made an impression on me.
I am interested in doing something in that spirit for my Tamil grammar lessons at https://www.learntamil.com. I’m happy about the positive feedback I’ve gotten from users over the years. Just a couple of years ago, a friend was refreshing his knowledge of Tamil using a language tutor whom he found through a website for online tutoring. My friend, in America, told the tutor, in Sri Lanka, about my language lesson website, and the tutor exclaimed, “Oh, you know the person who wrote that? I really like the way he structured his lessons. In fact, I reached out to him to ask him further questions.” Which is true. :-)
Tim and I did our work in a GitHub repository at https://github.com/echeran/smile-of-murugan.
You can find all the technical details there, of which there are a surprisingly non-trivial amount of, even though you would think it to be just a matter of digitizing a book. One example is fixing the OCR output for diacritics on the Latin letters. The reason is that academic literature about Indic languages tends to use a specific style of transliteration to represent in Latin script (for their English language text) that is consistent across all languages. In Tamil, there are short and long versions of many vowels, so you have a short o and a long ō, for instance. Also, in Tamil, there are 3 n’s and 2 r’s, and this transliteration scheme uses n, ṉ, ṇ and r, ṟ. For those representations of consonants, the combinations of base Latin letter (n, r) and the combining mark diacritics don’t appear as much in European languages that use the Latin script, as much as you would see ō or ā. As a result, the OCR made more mistakes on the consonants than the vowels. The mistakes meant that what should be a single word in Tamil, like மதுரைக்காஞ்சி, would was written as Maturaikkāñci, got converted by OCR into many incorrect forms, like Maturaikkañci, Maturaikkaňci, Maturaikkānci, Maturaikkāňci. Tim pushed for a system that we devised for doing such “spelling corrections”, where we could consolidate related and repeated “misspellings” from the OCR output for a single world. We created a map in Clojure where the key was the correct spelling, and the value is a collection of known misspellings. We updated the behavior of the map over time to allow typing the correct Tamil word in Tamil (ex: "மதுரைக்காஞ்சி" rather than "Maturaikkāñci"), and then also to indicate whether the word’s English transliteration needed to be capitalized (ex: [:t "மதுரைக்காஞ்சி"]).
I hope you’ll read the book. Please let me know about any corrections and/or indicate them in the GitHub repository.